DP-100 Online Practice Questions and Answers
HOTSPOT
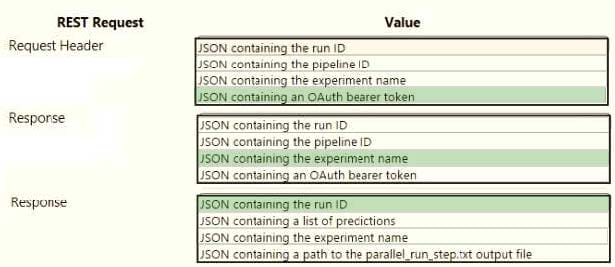
You publish a batch inferencing pipeline that will be used by a business application. The application developers need to know which information should be submitted to and returned by the REST interface for the published pipeline.
You need to identify the information required in the REST request and returned as a response from the published pipeline.
Which values should you use in the REST request and to expect in the response? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:

Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while
others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
An IT department creates the following Azure resource groups and resources:

The IT department creates an Azure Kubernetes Service (AKS)-based inference compute target named aks-cluster in the Azure Machine Learning workspace.
You have a Microsoft Surface Book computer with a GPU. Python 3.6 and Visual Studio Code are installed.
You need to run a script that trains a deep neural network (DNN) model and logs the loss and accuracy metrics.
Solution: Install the Azure ML SDK on the Surface Book. Run Python code to connect to the workspace and then run the training script as an experiment on local compute.
Does the solution meet the goal?
A. Yes
B. No
You create a new Azure subscription. No resources are provisioned in the subscription.
You need to create an Azure Machine Learning workspace.
What are three possible ways to achieve this goal? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. Run Python code that uses the Azure ML SDK library and calls the Workspace.create method with name, subscription_id, resource_group, and location parameters.
B. Use an Azure Resource Management template that includes a Microsoft.MachineLearningServices/ workspaces resource and its dependencies.
C. Use the Azure Command Line Interface (CLI) with the Azure Machine Learning extension to call the az group create function with --name and --location parameters, and then the az ml workspace create function, specifying 瓀 and 璯 parameters for the workspace name and resource group.
D. Navigate to Azure Machine Learning studio and create a workspace.
E. Run Python code that uses the Azure ML SDK library and calls the Workspace.get method with name, subscription_id, and resource_group parameters.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while
others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You create a model to forecast weather conditions based on historical data.
You need to create a pipeline that runs a processing script to load data from a datastore and pass the processed data to a machine learning model training script.
Solution: Run the following code:

Does the solution meet the goal?
A. Yes
B. No
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while
others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are analyzing a numerical dataset which contains missing values in several columns.
You must clean the missing values using an appropriate operation without affecting the dimensionality of the feature set.
You need to analyze a full dataset to include all values.
Solution: Replace each missing value using the Multiple Imputation by Chained Equations (MICE) method.
Does the solution meet the goal?
A. Yes
B. No
You are evaluating a completed binary classification machine learning model.
You need to use the precision as the evaluation metric.
Which visualization should you use?
A. violin plot
B. Gradient descent
C. Scatter plot
D. Receiver Operating Characteristic (ROC) curve
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You create an Azure Machine Learning service datastore in a workspace. The datastore contains the following files:
1.
/data/2018/Q1.csv
2.
/data/2018/Q2.csv
3.
/data/2018/Q3.csv
4.
/data/2018/Q4.csv
5.
/data/2019/Q1.csv
All files store data in the following format:
id,f1,f2,I 1,1,2,0 2,1,1,1 3,2,1,0 4,2,2,1
You run the following code:

You need to create a dataset named training_data and load the data from all files into a single data frame by using the following code:
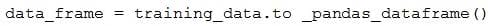
Solution: Run the following code: Does the solution meet the goal?

A. Yes
B. No
You run a script as an experiment in Azure Machine Learning.
You have a Run object named run that references the experiment run. You must review the log files that were generated during the experiment run.
You need to download the log files to a local folder for review.
Which two code segments can you run to achieve this goal? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. run.get_details()
B. run.get_file_names()
C. run.get_metrics()
D. run.download_files(output_directory='./runfiles')
E. run.get_all_logs(destination='./runlogs')
You are planning to register a trained model in an Azure Machine Learning workspace.
You must store additional metadata about the model in a key-value format. You must be able to add new metadata and modify or delete metadata after creation.
You need to register the model.
Which parameter should you use?
A. description
B. model_framework
C. tags
D. properties
You are in the process of carrying out feature engineering on a dataset.
You want to add a feature to the dataset and fill the column value.
Recommendation: You must make use of the Group Categorical Values Azure Machine Learning Studio module.
Will the requirements be satisfied?
A. Yes
B. No
You have a Jupyter Notebook that contains Python code that is used to train a model.
You must create a Python script for the production deployment. The solution must minimize code maintenance.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Refactor the Jupyter Notebook code into functions
B. Save each function to a separate Python file
C. Define a main() function in the Python script
D. Remove all comments and functions from the Python script
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You plan to use a Python script to run an Azure Machine Learning experiment. The script creates a reference to the experiment run context, loads data from a file, identifies the set of unique values for the label column, and completes the
experiment run:
from azureml.core import Run
import pandas as pd
run = Run.get_context()
data = pd.read_csv('data.csv')
label_vals = data['label'].unique()
# Add code to record metrics here
run.complete()
The experiment must record the unique labels in the data as metrics for the run that can be reviewed later.
You must add code to the script to record the unique label values as run metrics at the point indicated by the comment.
Solution: Replace the comment with the following code:
run.log_table('Label Values', label_vals)
Does the solution meet the goal?
A. Yes
B. No
You are implementing hyperparameter tuning for a model training from a notebook. The notebook is in an Azure Machine Learning workspace.
You must configure a grid sampling method over the search space for the num_hidden_layers and batch_size hyperparameters.
You need to identify the hyperparameters for the grid sampling.
Which hyperparameter sampling approach should you use?
A. uniform
B. qlognormal
C. choice
D. normal
You create an Azure Machine learning workspace.
You must use the Azure Machine Learning Python SDK v2 to define the search space for discrete hyperparameters. The hyperparameters must consist of a list of predetermined, comma-separated integer values.
You need to import the class from the azure.ai.ml.sweep package used to create the list of values.
Which class should you import?
A. Choice
B. Randint
C. Uniform
D. Normal
You create an Azure Machine Learning workspace.
You must use the Python SDK v2 to implement an experiment from a Jupyter notebook in the workspace. The experiment must log string metrics.
You need to implement the method to log the string metrics.
Which method should you use?
A. mlflow.log_artifact()
B. mlflow.log.dict()
C. mlflow.log_metric()
D. mlflow.log_text()
Why select/choose certbus.com?
Millions of interested professionals can touch the destination of success in exams by certbus.com. products which would be available, affordable, updated and of really best quality to overcome the difficulties of any course outlines. Questions and Answers material is updated in highly outclass manner on regular basis and material is released periodically and is available in testing centers with whom we are maintaining our relationship to get latest material.
![]()
![]()
Copyright © 2004-2025 certbus.com, All Rights Reserved.