DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST Online Practice Questions and Answers
Support vector machines (SVMs) are a set of supervised learning methods used for:
A. Linear classification
B. Non-linear classification
C. Regression
In which of the scenario you can use the linear regression model?
A. Predicting Home Price based on the location and house area
B. Predicting demand of the goods and services based on the weather
C. Predicting tumor size reduction based on input as number of radiation treatment
D. Predicting sales of the text book based on the number of students in state
Refer to Exhibit
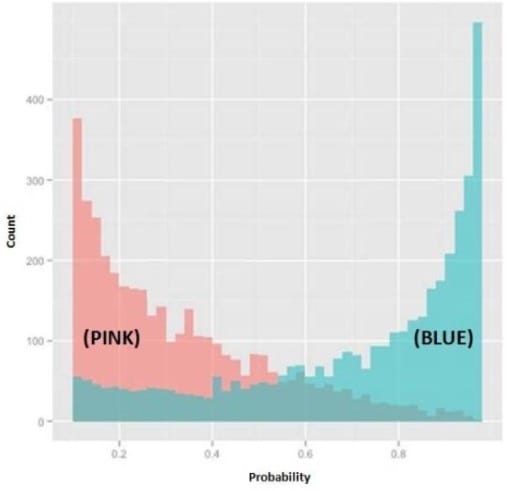
In the exhibit, the x-axis represents the derived probability of a borrower defaulting on a loan. Also in the exhibit, the pink represents borrowers that are known to have not defaulted on their loan, and the blue represents borrowers that are known to have defaulted on their loan. Which analytical method could produce the probabilities needed to build this exhibit?
A. Linear Regression
B. Logistic Regression
C. Discriminant Analysis
D. Association Rules
The method based on principal component analysis (PCA) evaluates the features according to:
A. The projection of the largest eigenvector of the correlation matrix on the initial dimensions
B. According to the magnitude of the components of the discriminate vector
C. The projection of the smallest eigenvector of the correlation matrix on the initial dimensions
D. None of the above
Refer to exhibit
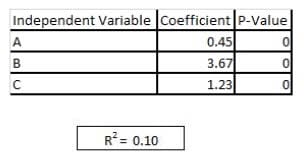
You are asked to write a report on how specific variables impact your client's sales using a data set provided to you by the client. The data includes 15 variables that the client views as directly related to sales, and you are restricted to these variables only. After a preliminary analysis of the data, the following findings were made: 1. Multicollinearity is not an issue among the variables 2. Only three variables-A, B, and C-have significant correlation with sales You build a linear regression model on the dependent variable of sales with the independent variables of A, B, and C. The results of the regression are seen in the exhibit. You cannot request additional data. what is a way that you could try to increase the R2 of the model without artificially inflating it?
A. Create clusters based on the data and use them as model inputs
B. Force all 15 variables into the model as independent variables
C. Create interaction variables based only on variables A, B, and C
D. Break variables A, B, and C into their own univariate models
Which technique you would be using to solve the below problem statement? "What is the probability that individual customer will not repay the loan amount?"
A. Classification
B. Clustering
C. Linear Regression
D. Logistic Regression
E. Hypothesis testing
What is the best way to evaluate the quality of the model found by an unsupervised algorithm like k-means clustering, given metrics for the cost of the clustering (how well it fits the data) and its stability (how similar the clusters are across multiple runs over the same data)?
A. The lowest cost clustering subject to a stability constraint
B. The lowest cost clustering
C. The most stable clustering subject to a minimal cost constraint
D. The most stable clustering
Consider the following confusion matrix for a data set with 600 out of 11,100 instances positive:
In this case, Precision = 50%, Recall = 83%, Specificity = 95%, and Accuracy = 95%.
Select the correct statement
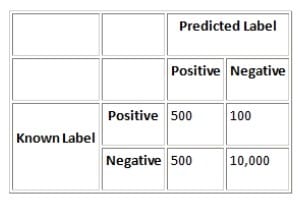
A. Precision is low, which means the classifier is predicting positives best
B. Precision is low, which means the classifier is predicting positives poorly
C. problem domain has a major impact on the measures that should be used to evaluate a classifier within it
D. 1 and 3
E. 2 and 3
You are using one approach for the classification where to teach the agent not by giving explicit categorizations, but by using some sort of reward system to indicate success, where agents might be rewarded for doing certain actions and
punished for doing others.
Which kind of this learning?
A. Supervised
B. Unsupervised
C. Regression
D. None of the above
Which of the following skills a data scientists required?
A. Web designing to represent best visuals of its results from algorithm.
B. He should be creative
C. Should possess good programming skills
D. Should be very good at mathematics and statistic
E. He should possess database administrative skills.
In which of the scenario you can use the regression to predict the values?
A. Samsung can use it for mobile sales forecast
B. Mobile companies can use it to forecast manufacturing defects
C. Probability of the celebrity divorce
D. Only 1 and 2
E. All 1 ,2 and 3
Of all the smokers in a particular district, 40% prefer brand A and 60% prefer brand B. Of those smokers who prefer brand A. 30% are females, and of those who prefer brand B. 40% are female. What is the probability that a randomly selected smoker prefers brand A, given that the person selected is a female?
Which of the following is a best way to solve this problem?
A. Bays Theorem
B. Poisson Distribution
C. Binomial Distribution
D. None of the above
Scenario: Suppose that Bob can decide to go to work by one of three modes of transportation, car, bus, or commuter train. Because of high traffic, if he decides to go by car. there is a 50% chance he will be late. If he goes by bus, which has special reserved lanes but is sometimes overcrowded, the probability of being late is only 20%. The commuter train is almost never late, with a probability of only 1 %, but is more expensive than the bus.
Suppose that Bob is late one day, and his boss wishes to estimate the probability that he drove to work that day by car. Since he does not know Which mode of transportation Bob usually uses, he gives a prior probability of 1 3 to each of the three possibilities. Which of the following method the boss will use to estimate of the probability that Bob drove to work?
A. Naive Bayes
B. Linear regression
C. Random decision forests
D. None of the above
Select the correct objectives of principal component analysis:
A. To reduce the dimensionality of the data set
B. To identify new meaningful underlying variables
C. To discover the dimensionality of the data set
D. Only 1 and 2
E. All 1, 2 and 3
Why select/choose certbus.com?
Millions of interested professionals can touch the destination of success in exams by certbus.com. products which would be available, affordable, updated and of really best quality to overcome the difficulties of any course outlines. Questions and Answers material is updated in highly outclass manner on regular basis and material is released periodically and is available in testing centers with whom we are maintaining our relationship to get latest material.
![]()
![]()
Copyright © 2004-2025 certbus.com, All Rights Reserved.