DS-200 Online Practice Questions and Answers
Why should stop an interactive machine learning algorithm as soon as the performance of the model on a test set stops improving?
A. To avoid the need for cross-validating the model
B. To prevent overfitting
C. To increase the VC (VAPNIK-Chervonenkis) dimension for the model
D. To keep the number of terms in the model as possible
E. To maintain the highest VC (Vapnik-Chervonenkis) dimension for the model
Certain individuals are more susceptible to autism if they have particular combinations of genes expressed in their DNA. Given a sample of DNA from persons who have autism and a sample of DNA from persons who do not have autism, determine the best technique for predicting whether or not a given individual is susceptible to developing autism?
A. Native Bayes
B. Linear Regression
C. Survival analysis
D. Sequence alignment
Refer to the exhibit.
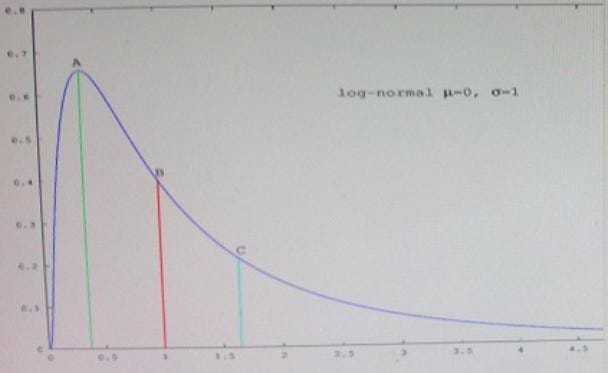
Which point in the figure is the mean?
A. A
B. B
C. C
There are 20 patients with acute lymphoblastic leukemia (ALL) and 32 patients with acute myeloid leukemia (AML), both variants of a blood cancer.
The makeup of the groups as follows:
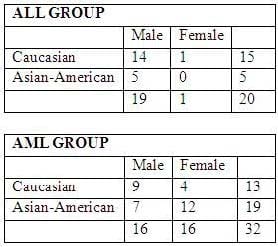
Each individual has an expression value for each of 10000 different genes. The expression value for each gene is a continuous value between -1 and 1.
You want to use the data from the 52 patients in the scenario to improve the ability of doctors being able to distinguish between ALL and AML. What type of data science problem is this?
A. Classification
B. Regression
C. Clustering
D. Filtering
There are 20 patients with acute lymphoblastic leukemia (ALL) and 32 patients with acute myeloid leukemia (AML), both variants of a blood cancer.
The makeup of the groups as follows: Each individual has an expression value for each of 10000 different genes. The expression value for each gene is a continuous value between -1 and 1.
With which type of plot can you encode the most amount of the data visually?
A. A heat map sorting the individuals by group
B. A histogram of the expression values
C. A scatter plot of two largest principal components
There are 20 patients with acute lymphoblastic leukemia (ALL) and 32 patients with acute myeloid leukemia (AML), both variants of a blood cancer.
The makeup of the groups as follows:
Each individual has an expression value for each of 10000 different genes. The expression value for each
gene is a continuous value between -1 and 1.
With which type of plot can you encode the most amount of the data visually?
Rather than use all 10,000 features to separate AML from ALL, you pick a small subnet of features to
separate them optimally. You feature vectors have 10,000 dimensions while you only have 52 data points. You use cross-validation to test your chosen set of features. What three methods will choose the features in an optimal way?
A. Singular value Decomposition
B. Bootstrapping
C. Markov chain Monte Carlo
D. Hidden Markov
E. Bayesian Information Criterion
F. Mutual Information
You have a large m x n data matrix M. You decide you want to perform dimension reduction/clustering on your data and have decide to use the singular value decomposition (SVD; also called principal components analysis PCA)
You performed singular value decomposition (SVD; also called principal components analysis or PCA) on you data matrix but you did not center your data first. What does your first singular component describe?
A. The mean of the data set
B. The variance of the data set
C. The standard deviation of the data set
D. The maximum of the data set
E. The median of the data set
You have a large m x n data matrix M. You decide you want to perform dimension reduction/clustering on your data and have decide to use the singular value decomposition (SVD; also called principal components analysis PCA)
Refer to the passage above.
What represents the SVD of the Matrix standard M given the following information:
U is m x m unitary V is n x n unitary S is m x n diagonal Q is n x n invertible D is n x n diagonal L is m x m lower triangular U is m x m upper triangular
A. M = U S V
B. M = U P
C. M = Q D Q-1
D. M = L U
You have a large m x n data matrix M. You decide you want to perform dimension reduction/clustering on your data and have decide to use the singular value decomposition (SVD; also called principal components analysis PCA)
For the moment, assume that your data matrix M is 500 x 2. The figure below shows a plot of the data.
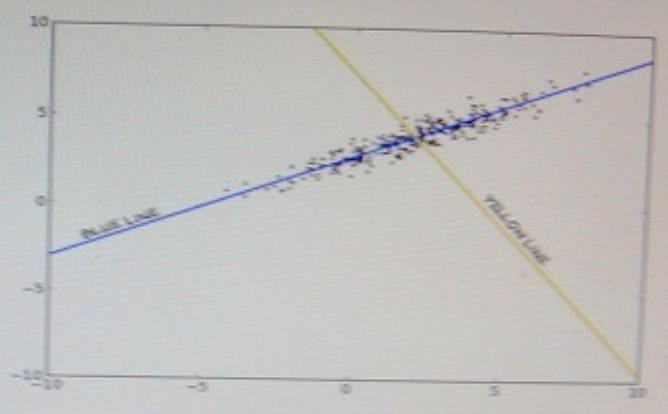
Which line represents the second principal component?
A. Blue
B. Yellow
Which two techniques should you use to avoid overfitting a classification model to a data set?
A. Include a small number "noise" features that are not through to be correlated with the dependent variable.
B. Replicate features that are through to be significant predicators of the dependent variable multiple time for each observation.
C. Separate your input data into a training set that is used for fitting and a test set that is used for evaluating the model's performance
D. Include a regularization term in the model's objective function to control how precisely the model fits the data
E. Preprocess the data to exclude a typical observation from the model input
Which recommender system technique is domain specific?
A. Content-based collaboration filtering
B. Item-based collaborative filtering
C. User-based collaborative filtering
D. Naïve Bayes classifier
You are building a system to perform outlier detection for a large online retailer. You need to build a system to detect if the total dollar value of sales are outside the norm for each U.S. state, as determined from the physical location of the buyer for each purchase. The retailer's data sources are scattered across multiple systems and databases and are unorganized with little coordination or shared data or keys between the various data sources.
Below are the sources of data available to you. Determine which three will give you the smallest set of data sources but still allow you to implement the outlier detector by state.
A. Database of employees that Includes only the employee ID, start date, and department
B. Database of users that contains only their user ID, name, and a list of every Item the user has viewed
C. Transaction log that contains only basket ID, basket amount, time of sale completion, and a session ID
D. Database of user sessions that includes only session ID, corresponding user ID, and the corresponding IP address
E. External database mapping IP addresses to geographic locations
F. Database of items that includes only the item name, item ID, and warehouse location
G. Database of shipments that includes only the basket ID, shipment address, shipment date, and shipment method
What are two defining features of RMSE (root-mean square error or root-mean-square deviation)?
A. It is sensitive to outliers
B. It is the mean value of recommendations of the K-equal partitions in the input data
C. It is the square of the median value of the error where error is the difference between predicted rating and actual ratings
D. It is appropriate for numeric data
E. It considers the order of recommendations
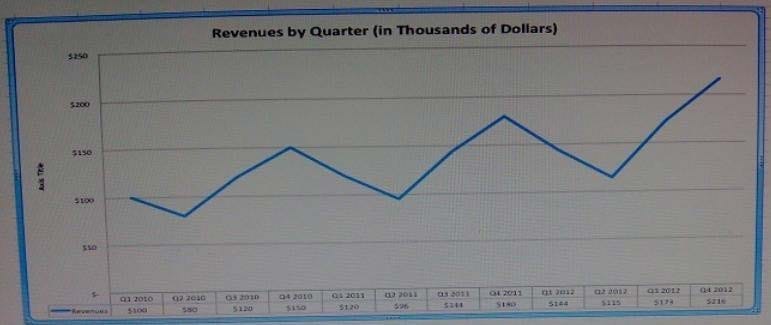
Assuming the trends shown in this chart continue, what would we expect the value of the revenue to be in Q1 of 2013?
A. $125,000
B. $170,000
C. $220,000
D. $250,000
From historical data, you know that 50% of students who take Cloudera's Introduction to Data Science: Building Recommenders Systems training course pass this exam, while only 25% of students who did not take the training course pass this exam. You also know that 50% of this exam's candidates also take Cloudera's Introduction to Data Science: Building Recommendations Systems training course.
What is the probability that any individual exam candidate will pass the data science exam?
A. 3/8
B. 1/4
C. 1/8
D. 1/2
Why select/choose certbus.com?
Millions of interested professionals can touch the destination of success in exams by certbus.com. products which would be available, affordable, updated and of really best quality to overcome the difficulties of any course outlines. Questions and Answers material is updated in highly outclass manner on regular basis and material is released periodically and is available in testing centers with whom we are maintaining our relationship to get latest material.
• 6000+ PDF and VCE exam dumps
• 6000+ Free demo downloads available
• 50+ Preparation Labs
• 20+ Representatives Providing 24/7 Support
![]()
![]()
Copyright © 2004-2024 certbus.com, All Rights Reserved.